
Mr.
Enron은 N1 for AIX 및 N14 Linux의 개발자로, AIX 운영 체제의 일부인 Enron for AIX를 개발했어요.
Mr.Enron은 LinkedIn과 YouTube에서 찾을 수 있으며, N1에 대한 약 300개의 동영상이 있어요.
Nsum은 nmon 요약포트로, 용량 계획 및 서버 통합에 적합합니다.
데이터의 파일 관리를 위해 InfluxDB 기반의 Jamon을 사용하여 nmon 파일을 관리하며, Grafana를 사용하여 데이터를 그래프로 표시하고, 긴 시간 동안의 추세 분석이 가능하다는 특징이 있어요.

영국에 있는 대규모 은행에서 서버 업그레이드를 요청했어요.
40개의 논리 파티션 또는 가상 머신을 돌리는 Power 7 서버들을 Power 10 머신으로 업그레이드하고자 해요.
업그레이드에 필요한 새로운 머신의 크기를 결정하기 위해 CPU, 메모리, 디스크 공간, 네트워크 트래픽을 확인해야 한답니다.
N1은 성능 모니터링 데이터를 수집하므로, 성능 조정에 유용하지만, 용량 계획과 서버 통합을 위해서는 해당 데이터를 요약하여 살펴봐야 해요.
야심차게 작업을 실행하기 전에 가장 바쁜 날을 선택하여 해당 데이터를 분석할 줄일 수 있어요.

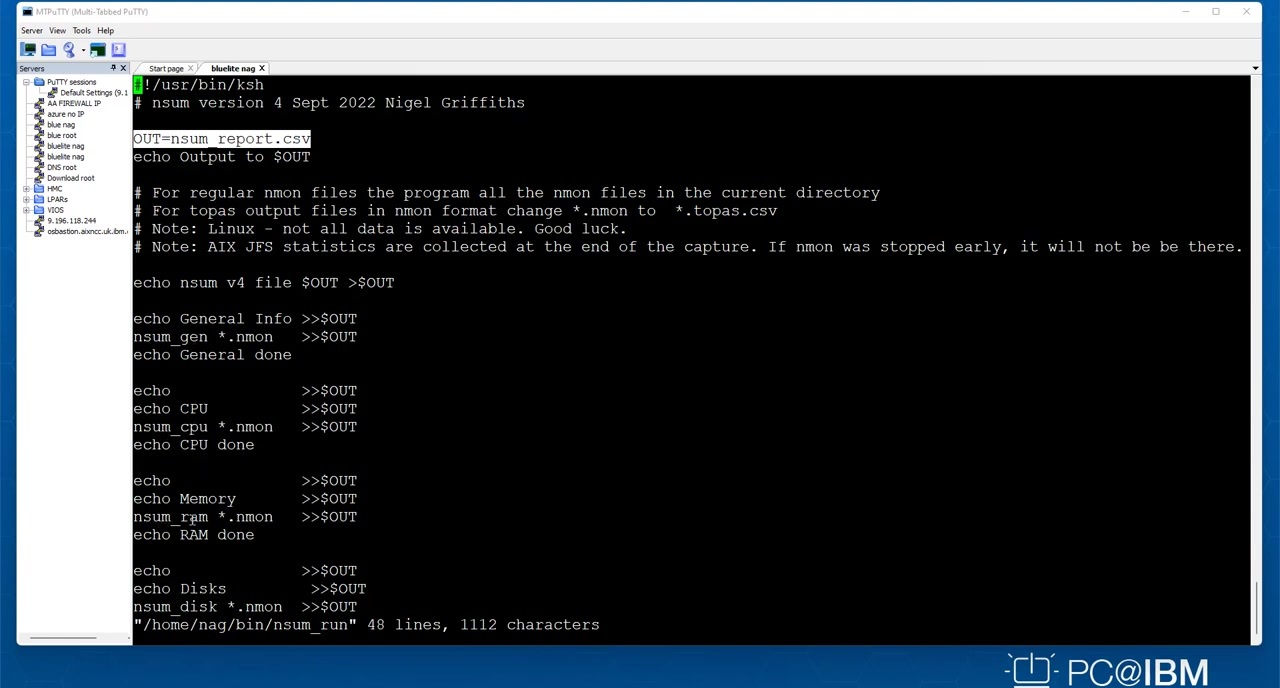
'nsum'은 N1 파일에서 관련된 정보를 추출하는 유용한 툴로, 총 일곱 개로 구성한 간단한 쉘 스크립트입니다.
여기서 CPU 정보에 대한 내용이 핵심이 되며, Jan 스크립트를 사용하면 머신 유형, 모델, 일련번호 및 CPU 유형 같은 일반 정보를 취합할 수 있습니다.
CPU 정보와 기타 기초 정보를 바탕으로 구체적인 용량 계획을 수립하며, 병렬 처리를 통해 대규모 데이터를 처리할 수 있습니다.
또한, 추출 방식은 95% 퍼센타일 방식으로 하여, 용량 고민 없이 더욱 정확한 머신 추천을 할 수 있는 장점이 있습니다.

유닉스 쉘 스크립트를 사용하여 NMON 데이터를 처리하는 방법을 알려드릴게요.
스탯이라 불리는 통계 별로 데이터를 정렬하고 상위 5%를 제외한 다음, 그 중 가장 큰 수를 95번째 퍼센타일이라고 하는데, 유닉스 쉘 스크립트로는 이런 작업이 4줄 정도로 가능합니다.
그리고 해당 보고서 파일은 CSV 형식으로 생성되며, 스프레드시트 프로그램에서 가져올 수 있습니다.
IBM의 AIX 운영체제를 사용하면서 Linux에서의 변경사항이 필요하다면 알려주라는 요청도 있네요.
NMON 데이터에는 개인 정보가 포함되어 있지 않아 다른 사람들에게 보여줘도 안전하니, 걱정하지 않아도 됩니다.
그리고 해당 파일은 윈즈 명령어를 사용하여 실행파일의 바이너리 정보를 확인할 수 있으며, 보고서 파일은 스크롤다운하여 확인할 수 있습니다.
네트워크, 파이버 채널, 저널 파일 시스템 등의 데이터를 분석해요.
상단에서는 열의 이름인 헤더를 출력하며, 중간에서는 CPU의 95% 백분위수를 계산하는 테스트를 진행합니다.
그리고 임시파일에 대한 처리, 유틸리티를 사용해 CPU 분석 등을 수행합니다.
마지막으로, 특정 파일에서 데이터를 읽어들여 결과를 출력합니다

임시 파일을 제거하고 종료하는 작업을 마친 뒤, 생성된 Azure 보고서 파일을 열어서 글꼴 크기를 줄여 가독성을 높였어요.
해당 보고서에는 다양한 정보들이 담겨 있으니 충분한 시간을 내어 자세히 살펴보는 것이 좋아요.
이 모든 과정은 매우 빠르게 수행됐어요.
최초 생성부터 보고서 완성까지 5초 정도 걸렸을 거에요.
보고서 파일은 기존 파일 목록에 추가되었으며, 제목을 'Azure 보고서'로 설정하여 구분할 수 있어요.

서버의 CPU, 메모리, 디스크, 네트워크 섹션을 살펴보며 데이터의 특징을 이해하고 있어요.
각 섹션에는 CPU, 메모리, 디스크, 네트워크와 관련된 정보가 제공돼요.
데이터의 크기가 바이트 단위이기 때문에 거대한 숫자가 보여주는 것이죠.
JFS 데이터 섹션에는 서버마다 다른 파일 시스템을 사용하기 때문에 평균 값을 구할 수 없어요.
Petabyte에 가까운 디스크 공간 중 실제로 사용되는 용량을 확인하기 위해 테스트를 수행했어요.

Windows Secure Copy(SCP)를 이용해서 AIX 머신 파일을 복사하여 엑셀에서 볼 수 있어요.
Excel에서 파일을 열 때는 컴마로 구분된 CSV 파일을 선택해야 합니다.
그러나 Excel에서 파일을 찾을 때는 반드시 모든 파일에서 찾도록 선택해야 하고, 조작적으로 글꼴 크기 등을 설정할 수 있는 강력한 기능이 있으며, 해당 파일에 보기 쉽게 정돈된 데이터를 쉽게 볼 수 있어요.
또한 CPU 정보, 메모리 정보, 디스크 정보, 네트워크 정보, 장애 발생 기록 등이 포함되어 있답니다.

전자 시트의 CPU를 찾은 뒤, 열을 추가해 더해서 결과를 내는 작업을 했어요.
그런데 데이터를 확인하던 중, 필요하지 않은 데이터가 포함되어 있는 것을 발견하여 삭제했어요.
그래서 이를 삭제하고 나서, 정상적으로 데이터를 볼 수 있게 되었어요.
마지막으로는 CPU 개수에 대한 소견을 진행하려고 했어요.

VP-to-E 숫자를 확인해보니 Linux 데이터에 문제가 있다는 것을 발견했어요.
이 중 900기가 정도가 걸쳐있는 Linux 파일이 문제가 되어, 삭제를 고려했습니다.
삭제 이전에 필요하면 데이터 분석을 거쳐 확인할 수 있지만, 이 데이터의 용량이 소중하지 않다고 판단해서 삭제하였습니다.
또한, Machine의 디스크와 I/O 작업을 확인해봤어요.
Network I/O와 Fiber Channel I/O의 어댑터 포트 수를 충분히 검토해야 하는데, 때로는 50대 컴퓨터에서 한 대의 컴퓨터로 나아갈 때 이 작업이 복잡해질 수 있습니다.
파워 7에 비해 네트워크 속도와 Fiber Channel 속도가 빨라졌기 때문에, 충분한 어댑터 포트를 사용해야합니다.
이 작업을 통해 문제를 해결하고 충분한 데이터 용량 확보 후, 인터페이스 매핑 프로젝트를 진행하였습니다.

이 차트에서는 14년간의 세대별 비교가 있으며, 32 CPU 코어 서버 (Power 6 ~10)의 R+ per core 값을 보여드려요.
Power 6부터 Power 10까지는 같은 기능 수행을 위해 더 많은 코어 개발에 노력하며 성능 최적화 하였고, 이번 Power 10에서는 코어 31-34개에도 R+ per core 207 달성 가능하게 하였답니다.
성능 개선을 위해 개발 과정에서 여러 어려움이 있었다고 해요.

IBM Power 성능 보고서에서 S10-32S 기계를 살펴보고 성능을 확인할 수 있었어요.
이 기계는 작은 것이지만 8코어로도 충분한 성능을 제공해 라이선스 비용, 운영체제 비용, 전력 사용량 모두 절감할 수 있었답니다.
사용한 문서의 링크가 제공되어 'Power 10'을 다룬 페이지와 'Power Performance Report' 링크도 확인할 수 있어요.
오래된 기기는 아카이브에서 확인 가능합니다.

PURSE를 이용해 사이징하는 방법에 대한 글을 작성했어요.
이는 유튜브 설명란에서 확인 가능해요.
서버 통합 등의 용량 계획할 때는 신중함이 필요하다는 것을 케이스 스터디를 통해 알게 되었어요.
잘못된 파일을 넣으면 완전히 잘못된 결과를 얻을 수 있기 때문에, 합리적인 검증과 적절한 머신 선택이 매우 중요합니다.
'AIX' 카테고리의 다른 글
| AIX 7.3에서 emgr_check_ifixes 사용하기 (0) | 2024.07.12 |
|---|---|
| Oracle용 AIX 튜닝 (0) | 2024.07.12 |
| AIX Tuning (0) | 2024.04.20 |
| AIX 포커스: 워크로드 관리자 (2) | 2023.12.08 |
| Nmon을 처음 사용하는 사람들을 위한 스타터 팩 (3) | 2023.12.01 |